
Echo & Chamber - How It Works
What’s up - thanks for reading my first blog post. I wanted a place to talk about some of the tech stuff and other things I work on & so this blog was born. This first post is a summary of the Echo & Chamber project I work on that came from my research project at Georgia Tech. If you are curious about the newsletter I added the most recent issue to the homepage so you can see what it is without sharing your email (or you could subscribe 😀).
![]()
Table of Contents
- Project Overview
- Connection to Georgia Tech Project
- Personal Learning Goals
- Architecture Overview
- Part 1: Crawler
- Part 2: Processor
- Article Embeddings
- Clustering
- Story Prioritization
- Story Generation
- Part 3: Editing + Publishing
Project Overview
Echo & Chamber in its current form gives a daily side-by-side look at how Fox News and MSNBC cover the same stories. For context, I’m a Wall Street Journal person (my happy place is reading it in a sauna, we get the print delivered), & I also like Morning Brew. I generally skip partisan cable news, but a ton of people consume those brands, and it has a material impact on political perception. So Echo & Chamber started as a way for me to quickly see how each side frames the same event. Not to doomscroll or argue, but to understand the lens other people are looking through.
When I launched I had more vague verbiage about left/right news, in actuality the current form of the letter is an analysis of how Fox News and MSNBC report on the same story. I changed the website copy because from a marketing perspective, I’m not sure telling people they’re in an echo chamber is the best approach. I want to lean more into curiosity/interest/entertainment. Fox News and MSNBC often treat each other as the boogeyman, liberals hate Fox & conservatives hate MSNBC. But I’m finding that regardless of political lean people do find the short Fox/MSNBC comparison an interesting way to stay up to date on misc political events.
The goal is really to be just a short digest of political events specifically through the lense of partisanship in an entertaining way. I also shortened the newsletter so it’s quick digestable items and not a lengthy read. Morning Brew was a big inspiration to the format, I’d love to have images but I don’t like AI generated images and using getty images is prohibitively expensive.
Connection to Georgia Tech Project
At Georgia Tech I took a course on Internet Research, which focused on monitoring the internet from both a content and technical perspective. The project my team did centered on tracking the spread of misinformation. I really enjoyed it, we built a tool to track stories by topic and then used predictive ML to analyze hosting attributes, looking for patterns that could help identify malicious actors.

Graduation day at GT
During my time at GT, most courses considered AI coding tools to be cheating. I think people not in the computer science world might be surprised that a CS degree is equal parts math and there is a lot that does not directly translate to actual software engineering. In the program I learned a lot about the math of machine learning / neural networks but actually very little about how to use the new AI coding tools that are coming out. So for me, I had this political news aggregator idea & I wanted to learn about coding with AI, there was a free student license for Cursor, the stars seemed to align so I went for it on the idea.
Personal Learning Goals
My main goal with this project was to learn and get experience with tech I don’t normally play with. This included building something complex with Cursor and also deploying multiple connected services to GCP. I needed it to be easy to operate once I built it, the goal being that the scraping of Fox and MSNBC is automated and I can just review/publish the newsletter. AI has its problems but the current models are very, very good at summarizing medium length articles. This leads to hallucination not being a problem because all context is contained in each LLM call. It also seemed like a fun way to think through a marketing exercise in how to attract subscribers.
In terms of learning goals I’d say the project has already been a success. I am planning to write a future blog post about using Cursor and my experience AI coding past a POC. If I could redo the build on this project no doubt it would be way cleaner & better, but I couldn’t have figured that out without actually doing it. It has also been interesting to go deeper on using GCP and designing with cost management top of mind (everything with this runs me about $20 a month).
Architecture Overview
The project has 3 main components:
- Crawler
- Processor (Generator)
- Editor + Publishing Flow
Part 1: Crawler
The crawler is relatively straightforward, using python I read the homepage of each Fox News and MSNBC hourly and index the top 20 articles. The idea here is that from a content perspective I am only interested in “top stories”, and by creating an hourly index I can track the story prominence and also how long it is at the top of their page. For each of the top 20 I copy the content into my index which can then be analyzed by the processor.
I built this using Cloud Functions in GCP triggered by a scheduler, and everything is saved to Cloud Storage buckets. I was surprised at how cost-efficient these services are when used at small scale, for hobby projects serverless is awesome. I did also try using actual databases but the costs were a lot higher because you need continually running compute, the file storage worked for me and is dirt cheap.
The crawler is its own code repo and overall I haven’t had much issue with the data collection. So, at this point I’ve collected an hourly snapshot of the top stories being posted with a prominence ranking, we are now ready to process the information.
Part 2: Processor
The processor application does the bulk of the lifting on the project. It is for sure the most complex code repo in my project. To summarize what it does:
- Extracts the article text from the files and creates an AI Embedding using the Sentence Transformer model from Hugging Face.
- Clusters each embedding to group the stories by topic.
- Prioritizes the topic matches based on what had the most prominence on the homepage for the longest time.
- Using the top matches from step 3, passes each story pair to the Anthropic API to generate the event summary and framing comparison (uses Sonnet class models).
2.1) Article Embeddings
Most people use AI through LLMs which are considered encoder/decoder models. AI is all based around math which essentially takes your input, turns it to numbers (encoder), processes it, and then outputs the response (decoder). With our goal here being to match stories by topic, we only need the encoder: it turns text into a vector of numbers (an “embedding”) that captures meaning. What happens is similar texts end up as nearby vectors, so we can compare them using math.
A simple example of this is a King and Queen. If you have the representation of King and subtract the idea of “man”, then add the idea of “woman”, in the vector space it winds up roughly putting you at queen. See below for a visual:
The open source Sentence Transformer model allows us to do this easily. The example above scales from single words to full articles to compare similarity.
2.2) Clustering
Clustering is a pretty simple machine learning concept. We have some threshold of “similarity score” and group our embeddings from step 1. If the embedding distance is close enough together, we say the stories are about the same topic. This drives the quality of the match and mostly just took some tuning of the score threshold - in machine learning we call this tuning a hyperparameter. We use this concept to pair the stories.
2.3) Story Prioritization
So now we have story pairs about the same topic and we want to rank them by “top story”. In lieu of trying to explain a complex algorithm in paragraph form I fed the code to Opus 4.1 and asked for a visual to explain the algorithm and it turned out good enough:
2.4) Story Generation
At this point we have a handful of story pairs with the story headline, text and URL for both articles. I pass this to the Anthropic API and use Sonnet to generate the summary. I have this flip back and forth so Fox/MSNBC change which is first so there are two prompts. I change this from time to time but at the time of this blog here are the prompts:
Part 3: Editing + Publishing
Alright so now we have a newsletter. The generator usually is pretty good but needs manual review. The output is raw HTML so I needed a way to quickly make edits since I plan to send this most weekdays. A bit of upfront work saves time every day on this, so I built a UI that allows me to quickly make edits to the letter, which you can see below:
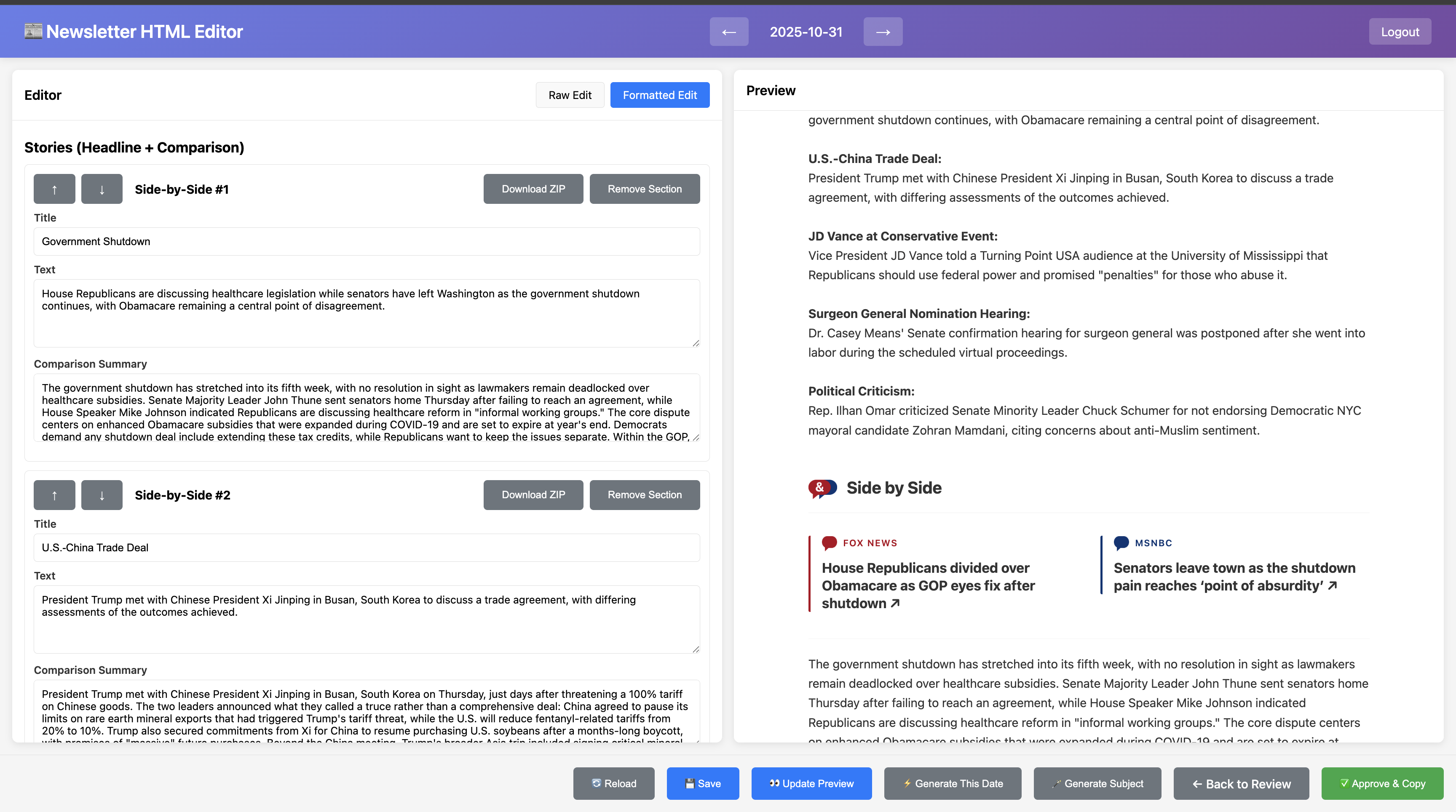
Editor UI I built to easily modify the HTML
It’s pretty nice and overall I enjoy reading the daily summary so it doesn’t feel like a chore and is just a part of my night routine. Typically it will match 1-2 stories that really don’t have to do with eachother so I’ll remove those and then send it out.
My publishing platform is Beehiiv which overall has been great except they don’t offer an API to publish the letter without an enterprise agreement. So the last step is I hop through their web UI and copy paste my letter to schedule for the following morning. Overall it takes about 10 minutes to read the letter and 5 minutes to schedule the send.
Conclusion
Overall this has been a fun project and I learned a lot, hopefully you enjoyed reading about it. The next learning for me here is how to market the idea without spending money. For my next post I plan to talk about some of what I learned using AI coding tools. Could certainly have gone way deeper here but this is long enough as it is, thanks for reading!!
- Mike